What if an AI model could argue with itself before giving you an answer? That is exactly what xAI's latest release does. Grok 4.2, launched as a public beta on February 17, 2026, marks a fundamental shift in how large language models work — replacing a single model with four specialized agents that deliberate, fact-check each other, and synthesize a consensus response in real-time.
The result: 65% fewer hallucinations and benchmark scores that position Grok among the top-tier models in the industry.
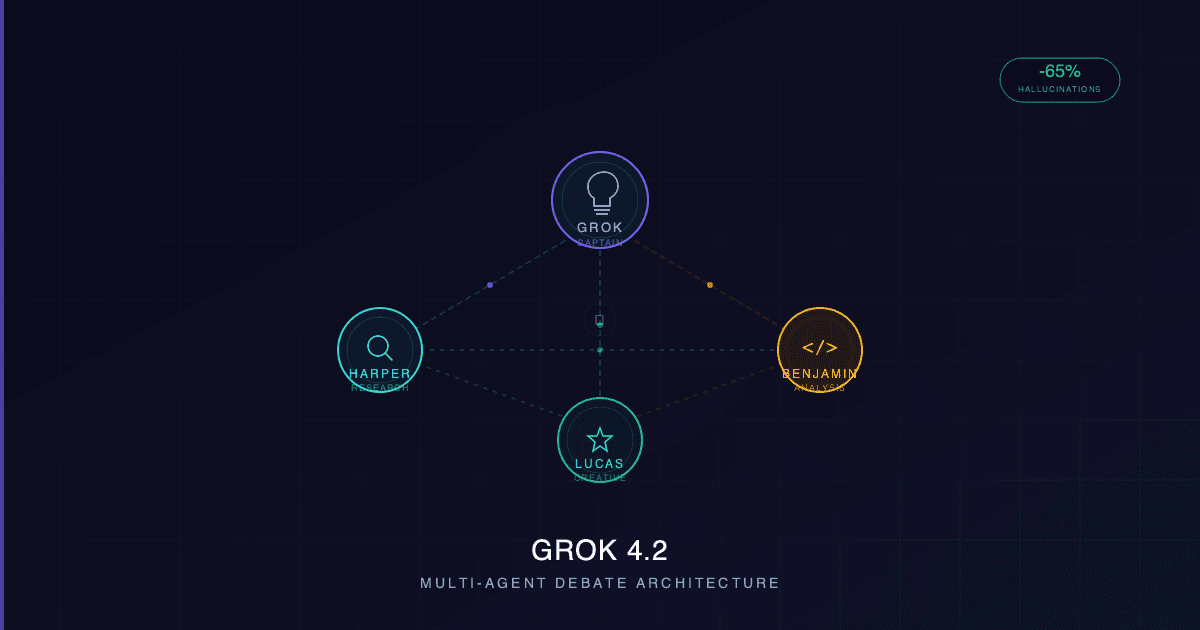
From One Model to Four Agents
Traditional LLMs process your prompt through a single neural network. No matter how large the model, it is one system doing everything — researching, reasoning, calculating, and composing. Grok 4.2 breaks this pattern entirely.
The system deploys four specialized agents, each with a distinct role:
- Grok (Captain) — The coordinator. Routes queries to the right agents, moderates the internal debate, and synthesizes the final response.
- Harper — The researcher and fact-checker. Has real-time access to X's data firehose (roughly 68 million English posts daily), cross-referencing claims against live sources.
- Benjamin — The analyst. Specializes in mathematics, code generation, and logical reasoning.
- Lucas — The communicator. Focuses on creative optimization, user experience, and making complex outputs clear and actionable.
When you send a prompt, all four agents process it in parallel. They then engage in multiple rounds of internal discussion — questioning each other's conclusions, flagging inconsistencies, and verifying facts — before Grok synthesizes their collective output into a single response.
Think of it as a panel of experts debating behind the scenes, with only the consensus reaching you.
Why Debate Reduces Hallucinations
Hallucinations — confident but incorrect outputs — remain one of the biggest unsolved challenges in AI. Single-model architectures hallucinate because they have no internal mechanism to cross-verify their own reasoning. The model generates text token by token, each choice influenced by statistical patterns rather than factual verification.
Grok 4.2's multi-agent debate addresses this structurally. When Harper fact-checks a claim that Benjamin generated, or Lucas flags a response that contradicts Harper's research, errors get caught before they reach the user. xAI reports a 65% reduction in hallucinations compared to Grok 4.1 — a number that reflects the architectural advantage of built-in cross-verification.
For comparison, OpenAI's GPT-5 achieves less than 1% hallucination error rate on open-source prompts through a different approach: scale and alignment tuning. Grok 4.2 uses architecture itself as the corrective mechanism, which may prove more adaptable as model capabilities grow.
Benchmarks: Where Grok 4.2 Stands
The numbers tell a compelling story. Grok 4.2's estimated Chatbot Arena ELO sits between 1505 and 1535 (provisional), potentially placing it alongside Gemini 3 Pro (1501 — the first model to cross the 1500 threshold) and GPT-5 in the top tier.
Where it really stands out:
| Benchmark | Grok 4.2 Result | Context |
|---|---|---|
| ForecastBench | #2 overall | Outperforms GPT-5, Gemini 3 Pro, Claude Opus 4.5 |
| Alpha Arena (Trading) | +34–47% returns | Only profitable model in the live competition |
| Hallucination Rate | -65% vs Grok 4.1 | Structural reduction via multi-agent verification |
| Arena ELO (est.) | 1505–1535 | Competitive with top-tier frontier models |
The Alpha Arena result is particularly striking. In a live stock trading competition, four Grok 4.2 variants took four of the top six spots, achieving average returns of 12.11% and peaks of 34–47%. No other model was consistently profitable. This suggests the multi-agent debate mechanism excels specifically in high-uncertainty domains where cross-verification of reasoning matters most.
Under the Hood
The raw specifications powering Grok 4.2:
- Parameters: ~3 trillion
- Context Window: 256K–2M tokens
- Training Infrastructure: Colossus supercluster (200,000 NVIDIA GPUs)
- Multimodal: Native text, image, and video processing
- Real-Time Data: X firehose integration (~68M English posts/day)
But the most distinctive technical feature is rapid learning. Unlike static models that require full retraining cycles for improvement, Grok 4.2 pushes weekly updates based on user feedback and performance data. Elon Musk confirmed that release notes accompany every update, making this the first frontier model to iterate in near real-time post-launch.
This is a fundamentally different deployment philosophy. While competitors release major versions quarterly, xAI treats Grok 4.2 as a living system that evolves continuously.
How It Compares to the Competition
The frontier AI landscape in February 2026 is more competitive than ever. Each major model has carved out distinct strengths:
| Grok 4.2 | GPT-5 | Gemini 3.1 Pro | Claude Opus 4.5 | |
|---|---|---|---|---|
| Architecture | Multi-agent (4) | Single model | Single model | Single model |
| Context | Up to 2M tokens | 400K tokens | 1M tokens | 200K tokens |
| Key Strength | Real-time data, low hallucinations | Math, reasoning, lowest error rate | Reasoning (ARC-AGI-2: 77.1%) | Code (SWE-Bench: 77.2%) |
| API Pricing | ~$0.20/$0.50 per M tokens | ~$5/M input | ~$1.25/M input | ~$15/M input |
| Update Cycle | Weekly | Quarterly | Periodic | Periodic |
Claude dominates software engineering tasks. Gemini leads reasoning benchmarks. GPT-5 excels in math with the lowest raw error rate. Grok 4.2's competitive edge is threefold: real-time data access through X integration, aggressive pricing that undercuts every competitor, and the structural advantage of multi-agent verification for accuracy-critical tasks.
The pricing gap is worth highlighting — at $0.20 per million input tokens, Grok 4.2 costs 25x less than GPT-5 and 75x less than Claude Opus for API access. For businesses processing large volumes, this changes the economics entirely.
What Multi-Agent AI Means for Businesses
Grok 4.2 is not just a product update. It signals where the entire industry is heading. Gartner predicts 40% of enterprise applications will embed AI agents by the end of 2026, up from less than 5% in 2025. Organizations already using multi-agent architectures report 45% faster problem resolution and 60% more accurate outcomes compared to single-agent systems.
The practical applications are already clear:
- Financial analysis — One agent pulls real-time market data, another runs quantitative models, a third validates assumptions. The synthesis is more reliable than any single model's output.
- Customer support — Research, policy lookup, and response agents working simultaneously reduce resolution time while maintaining accuracy.
- Software development — Specialized agents for code generation, testing, and documentation can work in parallel on a single feature request.
- Content verification — Fact-checking agents cross-reference claims before publication, critical for industries where accuracy is non-negotiable.
The trend is not limited to xAI. Google designed Gemini 3 explicitly for complex agentic operations. The broader industry is investing heavily in agent orchestration frameworks, and businesses that understand multi-agent architecture patterns now will have a significant advantage as this technology matures.
For companies evaluating AI strategy, the question is shifting from "which model?" to "which architecture?" Multi-agent systems are rapidly becoming the answer for high-stakes applications where accuracy matters more than raw speed.
Availability and Pricing
Grok 4.2 is currently available in public beta:
- Free tier — Available on grok.com with usage limits
- SuperGrok — $30/month for unlimited access
- X Premium+ — Included with subscription
- API — Expected to launch soon (~$0.20 input / $0.50 output per million tokens)
Key Takeaways
- Grok 4.2 replaces single-model architecture with four specialized agents (Grok, Harper, Benjamin, Lucas) that debate in real-time
- 65% hallucination reduction through structural cross-verification, not just model scaling
- Estimated Arena ELO of 1505–1535, competitive with GPT-5 and Gemini 3 Pro
- Only profitable model in Alpha Arena live stock trading competition (+34–47% returns)
- Weekly update cycle with rapid learning — a first for frontier AI models
- API pricing at $0.20/M tokens undercuts every major competitor by an order of magnitude
- Multi-agent AI reflects the industry's trajectory: Gartner projects 40% enterprise agent adoption by end of 2026
The shift from monolithic models to collaborative agent systems is accelerating. Whether you are building AI-powered products, evaluating models for enterprise deployment, or exploring how multi-agent architectures can transform your operations — Grok 4.2 makes one thing clear: the future of AI is not a single brilliant mind. It is a team.
Considering multi-agent AI for your business? Let's talk about the right architecture for your use case.


